ContextAVO: Local Context Guided and Refining Poses for Deep Visual Odometry
 The pipline of proposed LCD including DL-based feature extraction and adaptive similarity calculation
The pipline of proposed LCD including DL-based feature extraction and adaptive similarity calculation
Abstract
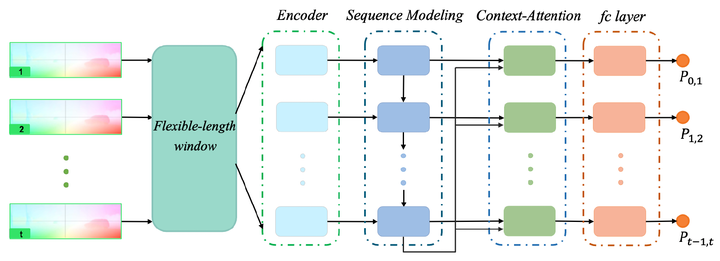
Learning-based monocular visual odometry (VO) has lately drawn significant attention for its potential in robustness to camera parameters and environmental variations. Different from most current learning-based methods, the proposed approach focuses on the effectiveness of local context and takes consecutive multiple optical flow sequences as the input. This paper presents a novel VO framework, called ContextAVO, which incorporates two additional components called Context-Attention Refining and flexible-length window. The Context-Attention Refining component ameliorates current inference using local dynamic context observation to guide motion estimation. The flexiblelength window considers the different receptive field sizes of the input to alleviate the severe dependence on the sequence length. Extensive experiments on the KITTI, Malaga, and ApolloScape benchmark datasets have demonstrated that the proposed method produces competitive results against the classic stereo VO algorithm and outperforms the state-of-the-art monocular methods by up to 23.18% and 47.55% for translational and rotational estimation, respectively.
Ran Zhu (朱然)
PhD candidate
My research interests include Visible Light Communication and Sensing, and Embedded AI for IoT.