ContextAVO: Local Context Guided and Refining Poses for Deep Visual Odometry
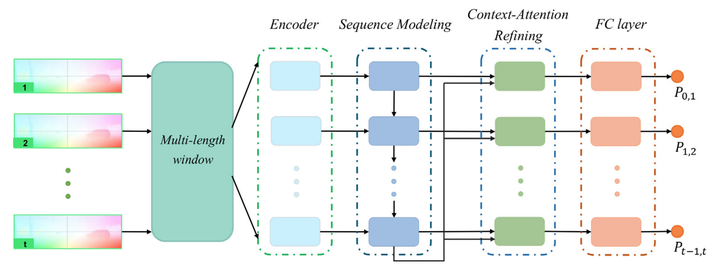 Image credit:
Unsplash
Image credit:
Unsplash
Abstract
Learning-based monocular visual odometry (VO) has lately drawn significant attention for its robustness to camera parameters and environmental variations. The correlation of ego-motion in the local time dimension, denoted as the local context, is crucial for alleviating accumulated errors of VO problems. Unlike most current learning-based methods, our approach, called ContextAVO, focuses on the effectiveness of local contexts to improve the estimation recovered from consecutive multiple optical flow snippets. To retain the pose consistency in the temporal domain, we design the Context-Attention Refining component to adaptively ameliorate current inference by exploiting the continuity of camera motions and aligning corresponding observations with local contexts. Besides, we employ the multi-length window to make ContextAVO more suitable for general scenarios and less dependent on the fixed length of the input snippet. Extensive experiments on outdoor KITTI, Malaga, ApolloScape, and indoor TUM RGB-D datasets have demonstrated that our approach efficiently produces competitive results against classic algorithms. It outperforms state-of-the-art methods by large margins, improving up to 7.40% and 48.56% for translational and rotational estimation, respectively.